Agentic AI Certification Training Course
- 133k Enrolled Learners
- Weekend/Weekday
- Live Class
(63442)





 Copy Link!
Copy Link!Attention mechanisms have altered modern artificial intelligence by allowing models to selectively focus on the most significant bits of an input, resulting in improved performance in tasks such as natural language processing and computer vision. From self-attention to multi-head attention, these methods provide the foundation of cutting-edge designs such as Transformers, allowing for effective handling of long-range dependencies. In this blog, we’ll look at how attention mechanisms function, how important they are, what their major components are, and how they will drive future AI innovation.
Attention processes have transformed deep learning models, particularly in the disciplines of natural language processing (NLP), computer vision, and others. They allow models to process particular sections of input sequences rather than the complete sequence. This principle is especially important for jobs with long-term dependencies. In this blog, we will look at the fundamental concepts underpinning attention mechanisms, how they function, and why they are necessary in modern AI systems.
An attention mechanism enables a model to concentrate on different parts of the input sequence while making predictions or performing a job. In other words, it enables the model to “attend” to select pieces of information more intently, rather than evaluating all data equally. Attention mechanisms are especially useful for tasks requiring the model to focus on elements of the input sequence that are more relevant to the current task.
For example, in machine translation, when translating a sentence from one language to another, certain words in the source language are more relevant to the current word being translated than others. An attention mechanism helps the model focus on these important words, improving accuracy.
Now, let’s explore how attention mechanisms actually work in practice.
The underlying principle behind attention is that each piece of an input sequence (such as a word in a phrase) is assigned a weight, reflecting its relative relevance to other parts. These weights are calculated dynamically, allowing the model to alter which sections of the input it processes.
A typical attention mechanism calculates three vectors for each element: Query, Key, and Value. These vectors are used to compute the attention weights:
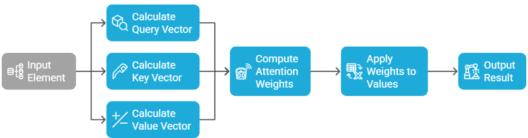
Query: Represents the current element being processed.
Key: Represents the other elements in the sequence.
Value: Represents the actual information that is carried by each element.
The attention score is computed by comparing the Query to the Keys using a similarity measure (often dot product), and the results are used to weigh the Values. The final output is a weighted sum of the Values.
import torch
import torch.nn.functional as F
# Example input: Queries, Keys, and Values (vectors)
queries = torch.tensor([[1., 0.], [0., 1.]]) # Query vectors
keys = torch.tensor([[1., 0.], [0., 1.]]) # Key vectors
values = torch.tensor([[1., 2.], [3., 4.]]) # Value vectors
# Calculate the dot product between queries and keys
scores = torch.matmul(queries, keys.T)
# Scale scores by the square root of the dimension of the key vectors
d_k = queries.size(-1)
scores = scores / torch.sqrt(torch.tensor(d_k, dtype=torch.float))
# Apply softmax to obtain attention weights
attention_weights = F.softmax(scores, dim=-1)
# Compute the weighted sum of the values (final attention output)
attention_output = torch.matmul(attention_weights, values)
print("Attention Weights:n", attention_weights)
print("Attention Output:n", attention_output)
The above code shows how attention weights are calculated and applied to the values to produce the final output. With this understanding, let’s dive into why attention mechanisms are so important in modern AI.
Attention mechanisms play a pivotal role in deep learning models, and here’s why they are so important:
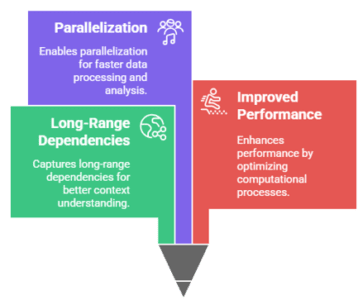
Capturing Long-Range Dependencies: Traditional models like RNNs struggle to capture long-range dependencies, while attention mechanisms can connect distant words or tokens in a sequence effectively.
Improved Performance: By focusing on the most relevant parts of the input, attention mechanisms help improve model performance on tasks like machine translation, text generation, and more.
Parallelization: Unlike RNNs, which process sequences step-by-step, attention mechanisms allow for parallelization of computations, leading to faster training times.
With these reasons in mind, let’s look at some practical use cases for attention mechanisms in AI applications.
Attention mechanisms have been used successfully in many AI tasks. Some key use cases include:
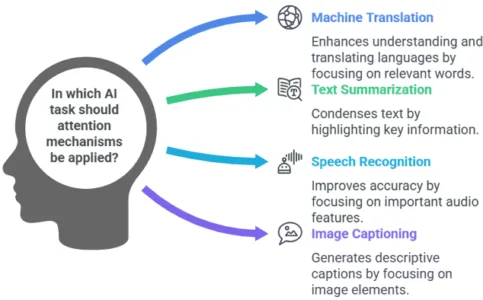
Machine Translation: Attention mechanisms help the model focus on the most relevant words in the source language when generating the translation.
Text Summarization: In abstractive text summarization, the model uses attention to focus on the most important parts of the document to generate a concise summary.
Speech Recognition: Attention can be applied to align the audio sequence with corresponding words in the transcript, improving recognition accuracy.
Image Captioning: Attention mechanisms are used in image captioning models to focus on different regions of the image while generating a description.
Text Generation: In models like GPT and BERT, attention helps the model generate coherent and contextually appropriate text.
These applications demonstrate the flexibility and importance of attention mechanisms, but what exactly are the components that make up an attention mechanism? Let’s break them down.
Attention mechanisms have become essential components of modern AI models due to their capacity to dynamically focus on pertinent elements of an input stream. Their relevance is understandable through the following significant advantages:
Attention mechanisms have transformed AI capabilities by increasing efficiency and effectiveness, paving the way for advances in deep learning systems. Now, let’s look at the key components that make attention processes so effective.
The main components of an attention mechanism include:
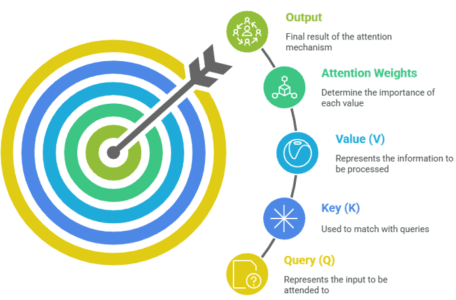
Query (Q): A vector representing the element being processed (e.g., a word in a sentence or a region in an image).
Key (K): A vector representing the other elements that the model will consider for relevance.
Value (V): A vector representing the actual information that will be passed on to the next layer or step in the process.
Attention Weights: Calculated based on the similarity between Queries and Keys, these weights determine the importance of each Value.
Output: A weighted sum of the Values, where the weights are determined by the attention mechanism.
Self-attention is a strategy that allows a model to process each word (or element) individually while weighing the significance of others in a sequence, thereby capturing relationships irrespective of position. Multi-head attention goes beyond this by running various self-attention processes in parallel, allowing the model to focus on multiple aspects of the input at the same time. These technologies, when combined, provide the foundation of modern designs such as Transformers, significantly improving their ability to grasp intricate data links.
Self-attention allows a model to consider other portions of the same input sequence when reaching a decision about a specific piece. It is especially effective in NLP tasks requiring the model to comprehend the relationship between words in a phrase, even if they are far apart.
For example, in the sentence “The cat sat on the mat,” self-attention enables the model to associate the word “cat” with “sat” and “mat,” understanding their relationships within the sentence.
Example: GPT Series and Self-Attention
The GPT series, like GPT-3, employs self-attention to produce coherent and contextually relevant language. The self-attention mechanism in GPT-3 aids the model in predicting the next word by taking into account all preceding words in the sentence or paragraph.
Multi-head attention is an expansion of the self-attention system. Instead of using a single attention mechanism, multi-head attention employs several attention mechanisms in tandem, each focused on a distinct part of the input sequence. The outputs from all attention heads are combined and linearly transformed.
This allows the model to capture various relationships between different parts of the input and improves its ability to understand complex patterns.
Example: Transformer Models
The Transformer architecture, widely used in models like BERT and GPT, relies on multi-head attention to capture different aspects of the input sequence simultaneously. This makes it highly effective for tasks requiring complex reasoning.
Vaswani’s “Attention is All You Need” work presented the Transformer architecture, which revolutionized NLP and AI by replacing recurrent or convolutional layers with attention methods. Transformers are made up of two parts: an encoder and a decoder. Both use multi-head self-attention processes. This design has served as the foundation for numerous cutting-edge models, including as BERT, GPT, and T5.
The Transformer is crucial for the advances we see in AI today, but it’s important to also look at the latest developments and research in attention mechanisms.
Recent advancements in attention mechanisms include:
Linformer: A more efficient transformer variant that approximates self-attention, reducing the computational cost.
Reformer: A model that uses reversible layers and locality-sensitive hashing to improve memory efficiency and scalability.
Longformer: A model designed to handle long documents by using a sliding window approach for attention.
These models demonstrate that researchers are actively working on improving the efficiency and scalability of attention mechanisms, especially for tasks involving long sequences or large datasets.
The future of attention mechanisms holds exciting potential. Researchers are exploring ways to:
Improve Efficiency: Making attention mechanisms more computationally efficient for large-scale models.
Cross-modal Attention: Applying attention mechanisms to multimodal tasks, where models process and correlate data from multiple sources (e.g., text, image, and audio).
Neuroscience-Inspired Models: Drawing inspiration from human attention processes to improve AI’s ability to mimic human cognition.
As these advancements unfold, attention mechanisms are likely to continue to be a foundational element in AI models, driving innovations across industries.
Many cutting-edge AI models, particularly those in natural language processing and computer vision, rely on attention processes. They enable models to focus on relevant aspects of the input while also capturing complex data dependencies. Whether it’s self-attention, multi-head attention, or advanced variations like Linformer and Longformer, attention mechanisms have proven useful in a range of tasks and continue to evolve as researchers look for new methods to improve them.
For a wide range of courses, training, and certification programs across various domains, check out Edureka’s website to explore more and enhance your skills!
1. What is a self-attention mechanism in generative AI?
Self-attention in generative AI refers to a model’s ability to consider all portions of an input sequence (such as a sentence) when producing output. This enables the model to produce more context-relevant and coherent replies.
2. What are attentional mechanisms?
Attentional mechanisms are strategies used in machine learning models that allow the model to concentrate on select areas of the input data and give them more weight throughout the learning or inference process.
3. How many attention mechanisms are there?
There are numerous sorts of attention processes, but the most prevalent include self-attention, multi-head attention, and variations such as local attention and global attention.
4. What are the 4 attentional styles?
The four attentional styles refer to different approaches or mechanisms in attention, such as:
Self-attention
Cross-attention (e.g., in encoder-decoder models like the Transformer)
Hard attention (discrete and selective focus)
Soft attention (continuous focus with a probabilistic weighting mechanism)
Related Posts: