
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!As is the case with scripts in other languages such as SQL, Unix Shell etc., Hive scripts are used to execute a set of Hive commands collectively. This helps in reducing the time and effort invested in writing and executing each command manually. This blog is a step by step guide to write your first Hive script and executing it.Check out this Big Data Course to learn more about Hive scripts and Commands in real projects.
Hive supports scripting from Hive 0.10.0 and above versions. Cloudera distribution for hadoop (CDH4) quick VM comes with pre-installed Hive 0.10.0 (CDH3 Demo VM uses Hive 0.90 and hence, cannot run Hive Scripts).
Execute the following steps to create your first Hive Script:
Open a terminal in your Cloudera CDH4 distribution and give the below command to create a Hive Script.
command: gedit sample.sql
The Hive script file should be saved with .sql extension to enable the execution.
Edit the file and write few Hive commands that will be executed using this script.
In this sample script, we will create a table, describe it, load the data into the table and retrieve the data from this table.
command: create table product ( productid: int, productname: string, price: float, category: string) rows format delimited fields terminated by ‘,’ ;
Here { productid, productname, price, category} are the columns in the ‘product’ table.
“Fields terminated by ‘,’ ” indicates that the columns in the input file are separated by the ‘,’ delimiter. You can use other delimiters also. For example, the records in an input file can be separated by a new line (‘
’) character.
command: describe product;
To load the data into the table, create an input file which contains the records that needs to be inserted into the table.
command: sudo gedit input.txt
Create few records in the input text file as shown in the figure.
Command: load data local inpath ‘/home/cloudera/input.txt’ into table product;
To retrieve the data use select command.
command: select * from product;
The above command will retrieve all the records from the table ‘product’.
The script should look like as shown in the following image:
 Save the sample.sql file and close the editor. You are now ready to execute your first Hive script.
Save the sample.sql file and close the editor. You are now ready to execute your first Hive script.
Execute the hive script using the following command:
Command: hive –f /home/cloudera/sample.sql
While executing the script, make sure that you give the entire path of the script location. As the sample script is present in the current directory, I haven’t provided the complete path of the script.
The following image shows that all the commands were executed successfully.
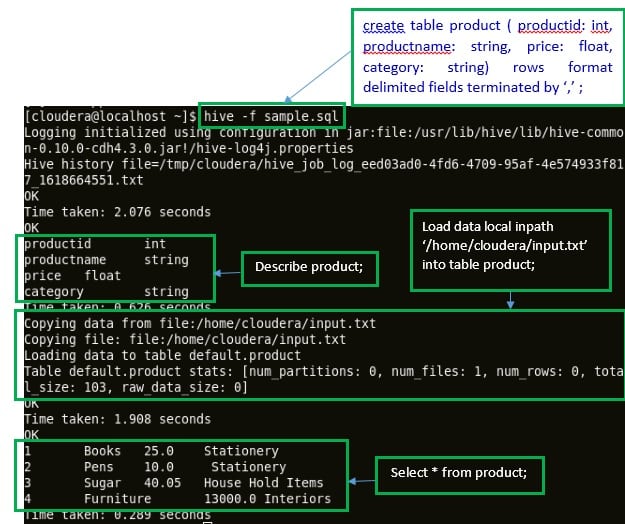
Congratulations on executing your first Hive script successfully!!!!. This Hive script knowledge is necessary to clear Big data certifications.







































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








what to do if i want to store the output in some directory and not show on command line?
Thank You very much..i got it
Thanks Siva! Please go through our other blog posts as well.
This is a nice post.Really useful
Thanks for providing Hive scripts.Please provide any other scripts for rest of tools like pig,hbase