
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!Hold on! Wait a minute and think before you join the race and become a Hadoop Maniac. Hadoop has been the buzz word in the IT industry for some time now. Everyone seems to be in a rush to learn, implement and adopt Hadoop. And why should they not? The IT industry is all about change. You will not like to be left behind while others leverage Hadoop. However, just learning Hadoop is not enough. What most of the people overlook, which according to me, is the most important aspect i.e. “When to use and when not to use Hadoop”
Resources to Refer:
You may also go through this recording of this video where our Hadoop Training experts have explained the topics in a detailed manner with examples.
In this blog you will understand various scenarios where using Hadoop directly is not the best choice but can be of benefit using Industry accepted ways. Also, you will understand scenarios where Hadoop should be the first choice. As your time is way too valuable for me to waste, I shall now start with the subject of discussion of this blog.If you know when to use Hadoop , then you easily understand the concepts and get the Big Data Certification.
Download Hadoop Installation Guide
First, we will see the scenarios/situations when Hadoop should not be used directly!
If you want to do some Real Time Analytics, where you are expecting result quickly, Hadoop should not be used directly. It is because Hadoop works on batch processing, hence response time is high.
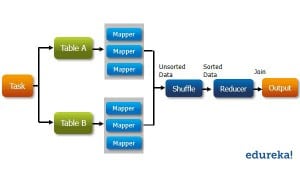
The diagram below explains how processing is done using MapReduce in Hadoop.
Real Time Analytics – Industry Accepted Way
Since Hadoop cannot be used for real time analytics, people explored and developed a new way in which they can use the strength of Hadoop (HDFS) and make the processing real time. So, the industry accepted way is to store the Big Data in HDFS and mount Spark over it. By using spark the processing can be done in real time and in a flash (real quick).

For the record, Spark is said to be 100 times faster than Hadoop. Oh yes, I said 100 times faster it is not a typo. The diagram below shows the comparison between MapReduce processing and processing using Spark

I took a dataset and executed a line processing code written in Mapreduce and Spark, one by one. On keeping the metrics like size of the dataset, logic etc constant for both technologies, then below was the time taken by MapReduce and Spark respectively.
This is a good difference. However, good is not good enough. To achieve the best performance of Spark we have to take a few more measures like fine-tuning the cluster etc.
[buttonleads form_title=”Download Installation Guide” redirect_url=https://edureka.wistia.com/medias/kkjhpq0a3h/download?media_file_id=67707771 course_id=166 button_text=”Download Spark Installation Guide”]
Resources to Refer:
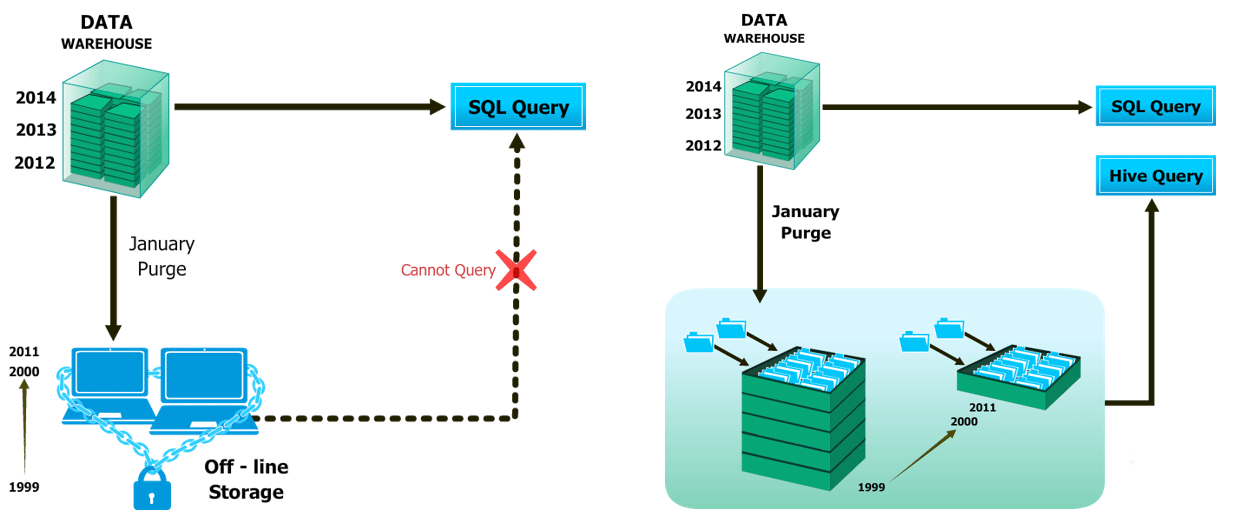
Hadoop is not a replacement for your existing data processing infrastructure. However, you can use Hadoop along with it.
Industry accepted way:
All the historical big data can be stored in Hadoop HDFS and it can be processed and transformed into a structured manageable data. After processing the data in Hadoop you need to send the output to relational database technologies for BI, decision support, reporting etc. You can get a better understanding with the Azure Data Engineer Certification.
The diagram below will make this clearer to you and this is an industry-accepted way.

Word to the wise:
Resources to Refer:
Hadoop framework is not recommended for small-structured datasets as you have other tools available in market which can do this work quite easily and at a fast pace than Hadoop like MS Excel, RDBMS etc. For a small data analytics, Hadoop can be costlier than other tools.
Industry Accepted Way:
We are smart people. We always find a better way. In this case, since all the small files (for example, Server daily logs ) is of the same format, structure and the processing to be done on them is same, we can merge all the small files into one big file and then finally run our MapReduce program on it.

In order to prove the above theory, we carried out a small experiment.
You can even check out the details of Big Data with the Data Engineering Training in Chennai.
The diagram below explains the same:

We took 9 files of x mb each. Since these files were small we merged them into one big file. The entire size was 9x mb. (Pretty simple math: 9 * x mb = 9x mb )
Finally, we wrote a MapReduce code and executed it twice.
So as you can see the second execution took lesser time than the first one. Hence, it proves the point.
Resources to Refer:
Unless you have a better understanding of the Hadoop framework, it’s not suggested to use Hadoop for production. Hadoop is a technology which should come with a disclaimer: “Handle with care”. You should know it before you use it or else you will end up like the kid below.

Learning Hadoop and its eco-system tools and deciding which technology suits your need is again a different level of complexity
Resources to Refer:
Many enterprises — especially within highly regulated industries dealing with sensitive data — aren’t able to move as quickly as they would like towards implementing Big Data projects and Hadoop.

Industry-Accepted way
There are multiple ways to ensure that your sensitive data is secure with the elephant (Hadoop).
Finally, you use the data for further MapReduce processing to get relevant insights.

The other way that I know and have used is using Apache Accumulo on top of Hadoop. Apache Accumulo is sorted, distributed key/value store is a robust, scalable, high performance data storage and retrieval system.
Ref: https://accumulo.apache.org/
What they missed to mention in the definition that it implements a security mechanism known as cell-level security and hence it emerges as a good option where security is a concern.
Resources to Refer:
When you are dealing with huge volumes of data coming from various sources and in a variety of formats then you can say that you are dealing with Big Data. In this case, Hadoop is the right technology for you.

Resources to Refer:
It is all about getting ready for challenges you may face in future. If you anticipate Hadoop as a future need then you should plan accordingly. To implement Hadoop on you data you should first understand the level of complexity of data and the rate with which it is going to grow. So, you need a cluster planning. It may begin with building a small or medium cluster in your industry as per data (in GBs or few TBs ) available at present and scale up your cluster in future depending on the growth of your data.

Resources to Refer:
There are various tools for various purposes. Hadoop can be integrated with multiple analytic tools to get the best out of it, like Mahout for Machine-Learning, R and Python for Analytics and visualization, Python, Spark for real time processing, MongoDB and Hbase for Nosql database, Pentaho for BI etc.
I will not be showing the integration in this blog but will show them in the Hadoop Integration series. I am already excited about it and I hope you feel the same.

Resources to Refer:
When you want your data to be live and running forever, it can be achieved using Hadoop’s scalability. There is no limit to the size of cluster that you can have. You can increase the size anytime as per your need by adding datanodes to it with minimal cost.
The bottom line is to use the right technology as per your need.
The Edureka’s Big Data Architect Course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Posts:




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








Hi, we are at a certain state, where we are thinking if we should get rid of our MySQL cluster. The cluster has about 500GB of data spread across approximately 100 databases. A lot of these use cases we have are around relational queries as well.
Between, spark and Impala, I am wondering if we should just get rid of MySQL. I somehow feel that our use case for MySQL isn’t really BigData as the databases won’t grow to TBs. also, I am not sure if pumping everything into HDFS and using Impala and /or Spark for all reads across several clients is the right use case. In traditional databases we used to have read only databases so that reads and reporting won’t imact our processing later. Putting all processing, reading into 1 single cluster seems like a design for single point of failure.
Do you have any point of view on this?
When Not use SPARK
Hey Sagar, thanks for checking out our blog.
When it comes to unstructured data, we use Pig instead of Spark.
Hope this helps. Cheers!
why we use hadoop?
I guess the 2nd section should be titled as “When to use Hadoop”
Thanks for highlighting this. We have made the necessary changes.